Un investigador de la UAB participa en l'obtenció del primer esborrany del pangenoma humà
Santiago Marco-Sola, investigador del Departament d'Arquitectura de Computadors i Sistemes Operatius i del Barcelona Supercomputing Center (BSC), i el seu equip han desenvolupat algorismes i eines computacionals d’alt rendiment que han contribuït a l’obtenció del primer esborrany del pangenoma humà. L’estudi, dut a terme per un consorci internacional d’investigadors, s’ha publicat a la revista Nature.
12/05/2023
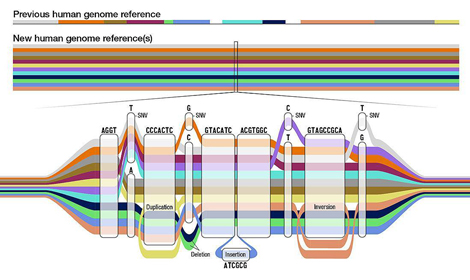
El primer esborrany del pangenoma humà, desenvolupat pel consorci Human Pangenome Reference Consortium (HPRC), supera la referència lineal i basada en poques persones del primer genoma humà, seqüenciat fa dues dècades. Mitjançat una estructura de grafo, el nou pangenoma permet modelar les variacions genòmiques que hi ha en diferents individus de la nostra espècie. En aquesta primer versió s’han reconstruït amb alta precisió i fiabilitat els genomes de 47 individus de diverses parts del món amb ancestres diferents (africans, americans, asiàtics i europeus). El consorci pretén augmentar aquesta xifra fins a 350 els propers anys.
Per entendre quins eren els mètodes i eines més adequats per a la construcció del pangenoma i l’anàlisi posterior, l’HPRC ha analitzat diversos mètodes computacionals d’alt rendiment. Un dels mètodes utilitzats ha estat el desenvolupat per Santiago Marco-Sola i el seu equip a la UAB i al BSC: un algorisme per a l’alineament de seqüències genòmiques (WFA, wavefront alignment algorithm), que millora en eficiència i escalabilitat altres mètodes.
«La construcció d'un pangenoma és complexa i comporta diferents fases d'anàlisis i processament de les dades, atès que requereix volums enormes de dades genòmiques. Els mètodes i programes per a l’assemblatge i processament de dades genòmiques estan compostos per múltiples fases que requereixen usar algorismes complexos i costosos. Per això, aquest projecte no seria possible sense computadors d’altes prestacions, atès que només supercomputadors com el Marenostrum4 tenen la capacitat de processar i emmagatzemar quantitats de dades tan grans», assenyala Santiago Marco-Sola.
L'estudi del pangenoma publicat afegeix 119 milions de parells de bases de l’ADN i 1.115 duplicacions de gens i augmenta la quantitat de variants estructurals detectades en un 104 %. Això permetrà representar desenes de milers de noves variants genòmiques en regions genòmiques inaccessibles fins ara i accelerar la investigació clínica, en millorar la comprensió del vincle entre els gens i els trets de les malalties.
Article: Liao, WW., Asri, M., Ebler, J. et al. «A draft human pangenome reference». Nature 617, 312–324 (2023). https://doi.org/10.1038/s41586-023-05896-x